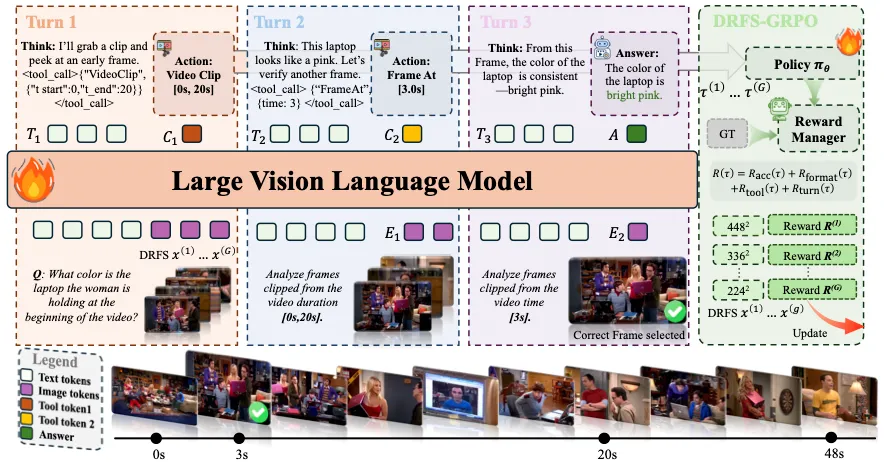
We propose FrameMind, an RL-trained framework that learns to actively sample video frames while it reasons. This dynamic perception overcomes the limits of static models and achieves state-of-the-art results.
Current video understanding models rely on fixed frame sampling strategies, processing predetermined visual inputs regardless of the specific reasoning requirements of each question. This static approach limits their ability to adaptively gather visual evidence, leading to suboptimal performance on tasks requiring either broad temporal coverage or fine-grained spatial detail. In this paper, we introduce FrameMind, a novel end-to-end framework trained with reinforcement learning that enables models to dynamically request visual information during reasoning through Frame-Interleaved Chain-of-Thought (FiCOT). Unlike traditional approaches, FrameMind operates in multiple turns where the model alternates between textual reasoning and active visual perception, using tools to extract targeted frames or video clips based on identified knowledge gaps. To train effective dynamic sampling policies, we propose Dynamic Resolution Frame Sampling (DRFS), which exposes models to diverse temporal–spatial trade-offs during learning, and DRFS-GRPO, a group-relative policy optimization algorithm that learns from outcome-based rewards without requiring frame-level annotations. Extensive experiments on challenging benchmarks like MLVU and VideoMME demonstrate that our method significantly outperforms existing models, advancing the state of the art in flexible and efficient video understanding.
@article{ge2025framemind,
title={FrameMind: Frame-Interleaved Chain-of-Thought for Video Reasoning via Reinforcement Learning},
author={Ge, Haonan and Wang, Yiwei and Chang, Kai-Wei and Wu, Hang and Cai, Yujun},
journal={arXiv preprint arXiv:2509.24008},
year={2025}
}